这篇论文是最近参加组会看的一篇新论文,论文虽然是2016年出的论文,但是它是YouTube发表的,且是应用在YouTube这样超级大的平台上的一篇工业界的推荐系统的论文,我读完之后也觉得论文有一些可取之处的,所以和大家分享一下我的组会ppt汇报。
YouTube是世界上最大的视频创作及分享平台,其视频推荐面临的主要问题有:
- Scale(用户量巨大):现有的推荐算法通常在小数据集有良好的表现,但是在YouTube这样规模的数据集上未必表现良好。
- Freshness(新鲜度):YouTube系统每秒钟都有大量新视频上传(实时性),推荐系统应该能够快速的对视频及用户行为作出反馈,并平衡新老视频的综合推荐。
- Noise(噪声): 用户的历史行为往往是稀疏的并且不完整的,同时视频本身很多数据都是非结构化的,这两点对推荐算法的鲁棒性提出了挑战。
Youtube的用户推荐场景自不必多说,作为全球最大的UGC(用户生成内容)视频网站,需要在百万量级的视频规模下进行个性化推荐。由于候选视频集合过大,考虑online系统延迟问题,不宜用复杂网络直接进行推荐,所以Youtube采取了两层深度网络完成整个推荐过程:
- Candidate Generation Model 即候选生成模型(也叫召回模型)
- Ranking Model 排序模型
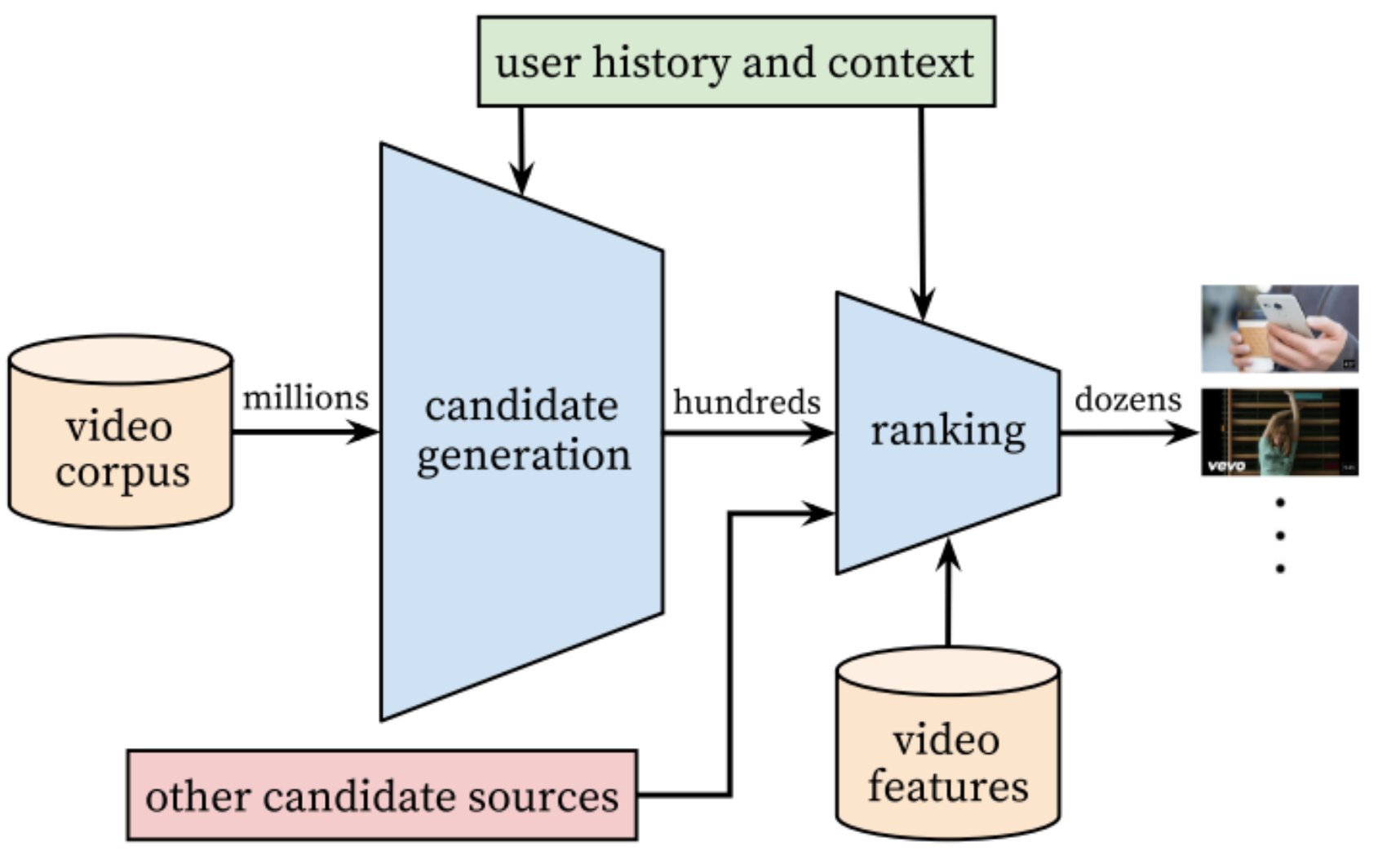
下图是本文的推荐系统模型架构图,视频池子中包含有亿级别个视频,当经过第一层候选生成层模型时,这层主要是做粗略的筛选,视频被过滤为只有百级别个视频,再次经过第二层模型时,这层会将视频进行打分排序,然后筛选出前几十个视频,输出到用户的视频主页上,供用户观看,如下图所示:
,
CANDIDATE GENERATION 候选生成模型
这一层模型用两个字概括就是“粗糙”,将视频池子中的数百亿的视频,经过第一层筛选得到数百个视频,传入到下一层模型进一步训练。
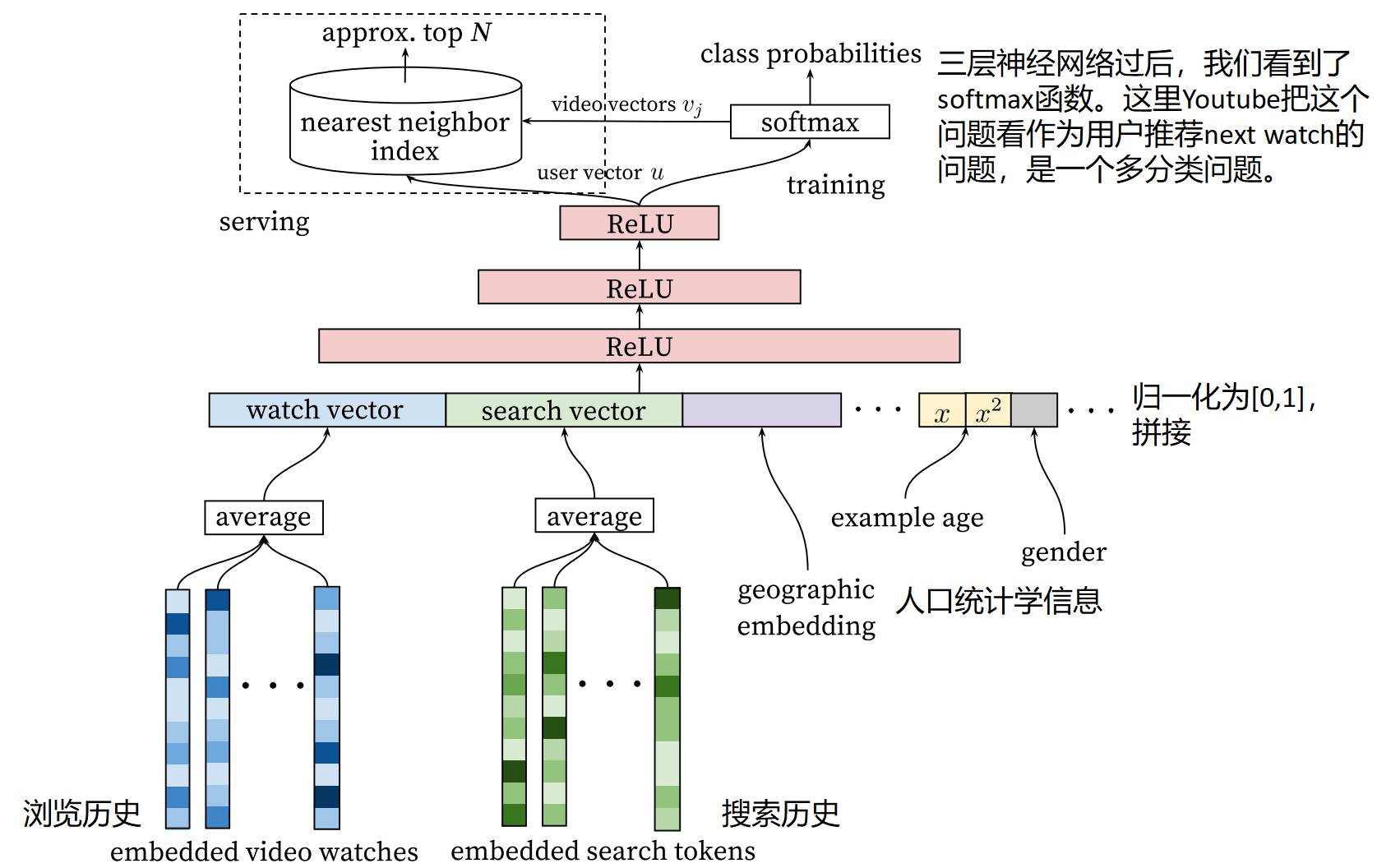
下图是候选生成模型的的模型架构图,从下往上看,将浏览历史、搜索历史特征嵌入为高层embedded向量,还会加入其他有关用户画像的特征,如地理位置、年龄、性别等特征,将这些人口统计学信息归一化到[0,1]范围中,与前面的特征进行拼接,然后将所有的特征喂给上层的神经网络模型,经过三层神经网络后,我们可以看到softmax函数。这里YouTube把这个问题看作为用户推荐next watch的问题,是一个多分类的问题。
候选集生成建模为一个“超大规模多分类”问题其分类公式如下图式所示:
在时间t时,用户U在其特定的上下文C,对指定的视频wt准确的划分到第i类中。
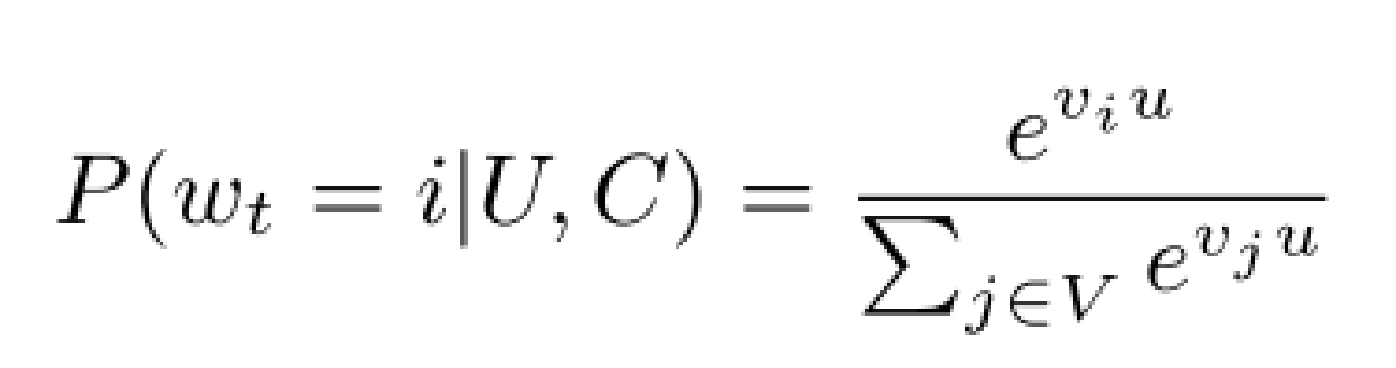
其中u是用户和其上下文的高维embedded嵌入,v是视频的高维embedded嵌入。
针对该架构,有如下几点值得关注:
(1) 主要特征的处理1:watch and search 浏览历史和搜索历史。
视频存在于手机等设备上,是一串稀疏的,变长的视频ID序列,通过固定的词汇表,经过加权平均,可以基于其重要性或时间,得到一串稠密的,定长的观看向量,输入到上层神经网络中,如下图所示:

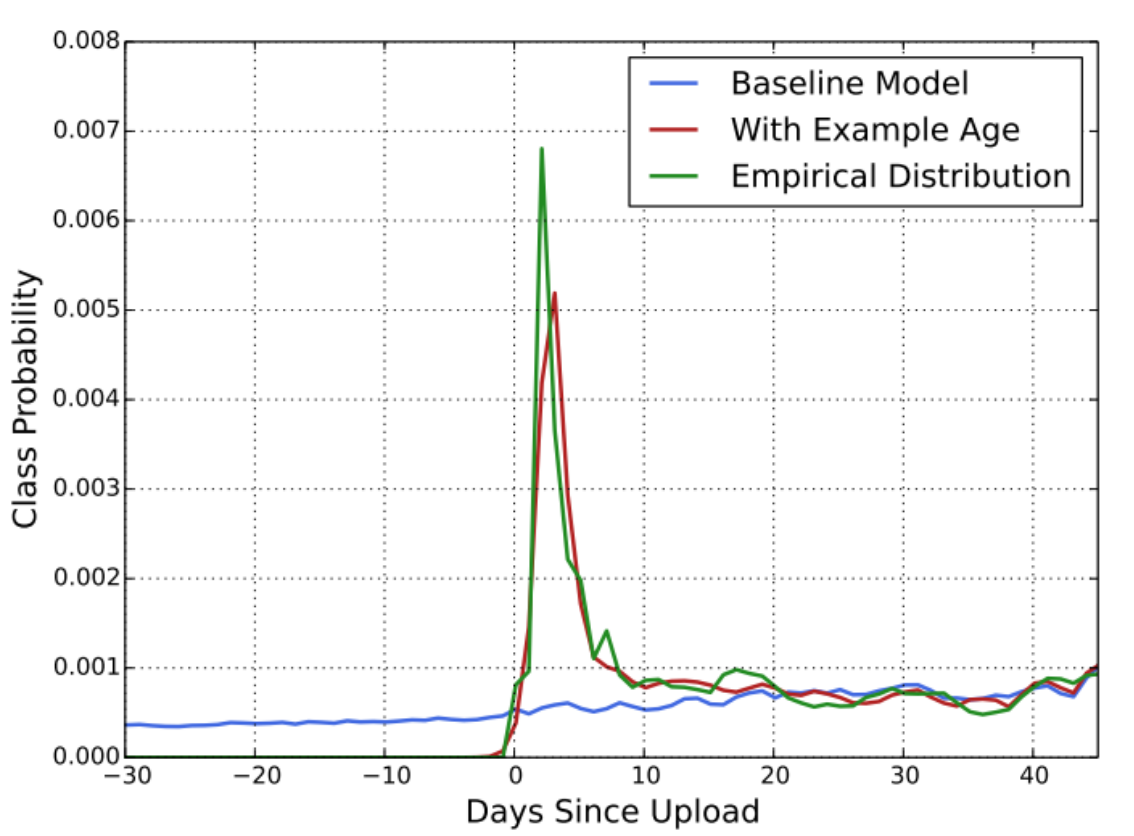
主要特征的处理2:example age 视频上传时间
如下图所示,横坐标是视频上传的时间,轴坐标是类别概率,在没有加入到example age特征时,可以注意到这条蓝色的线,一直表现的很平平,加入了此特征,类别的概率更加符合按经验分布,说明这个特征的重要性。
(2) 上下文选择
用户观看视频时,遵循一种asymmetric co-watch非对称共同观看,用户在浏览视频时,往往都是序列式的,开始看一些比较流行的逐渐找到细分的视频。
如下图所示,(a)图是利用上下文信息预估中间的一个视频,(b)图是利用上下文信息,预估下一次浏览的视频,显然,预测下一次浏览的视频比预测中间的一个视频要简单的多。
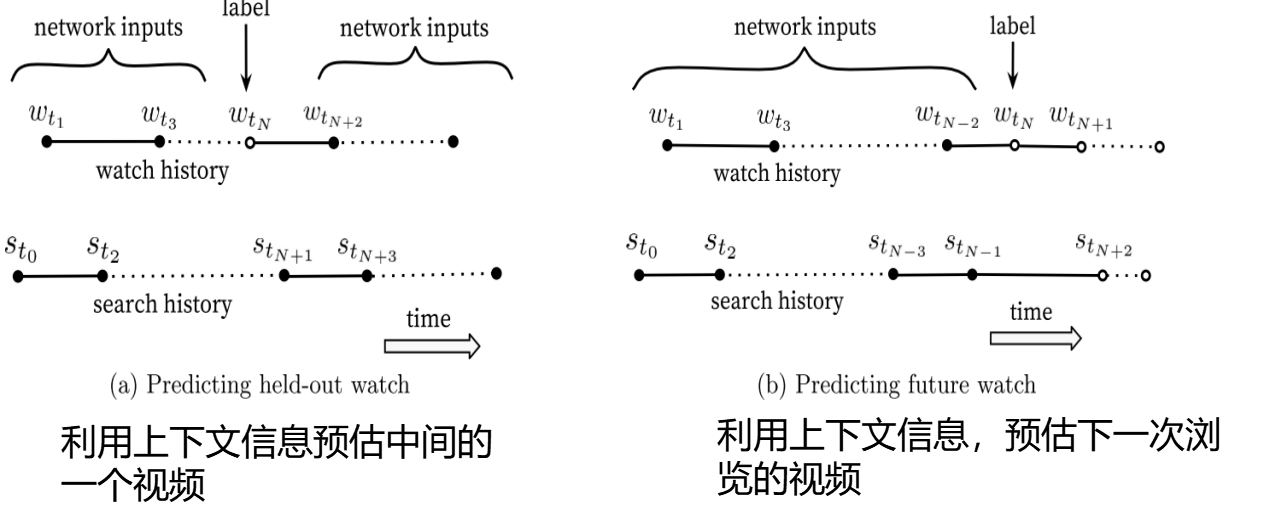
通过实验也可以发现,图(b)的方式在线上A/B test中表现更佳,而实际上,传统的协同过滤类算法,都是隐含采用图(a)方式,忽略了不对称的浏览方式。
(3) 特征集以及深度的实验
如下图所示,神经网络模型采用的是经典的“tower”模式搭建网络,所有的视频和搜索历史都embedded到256维的向量中,开始在input层直接全连接到256维的softmax层,然后依次增加网络深度(+512–>+1024–>+2048–> …)

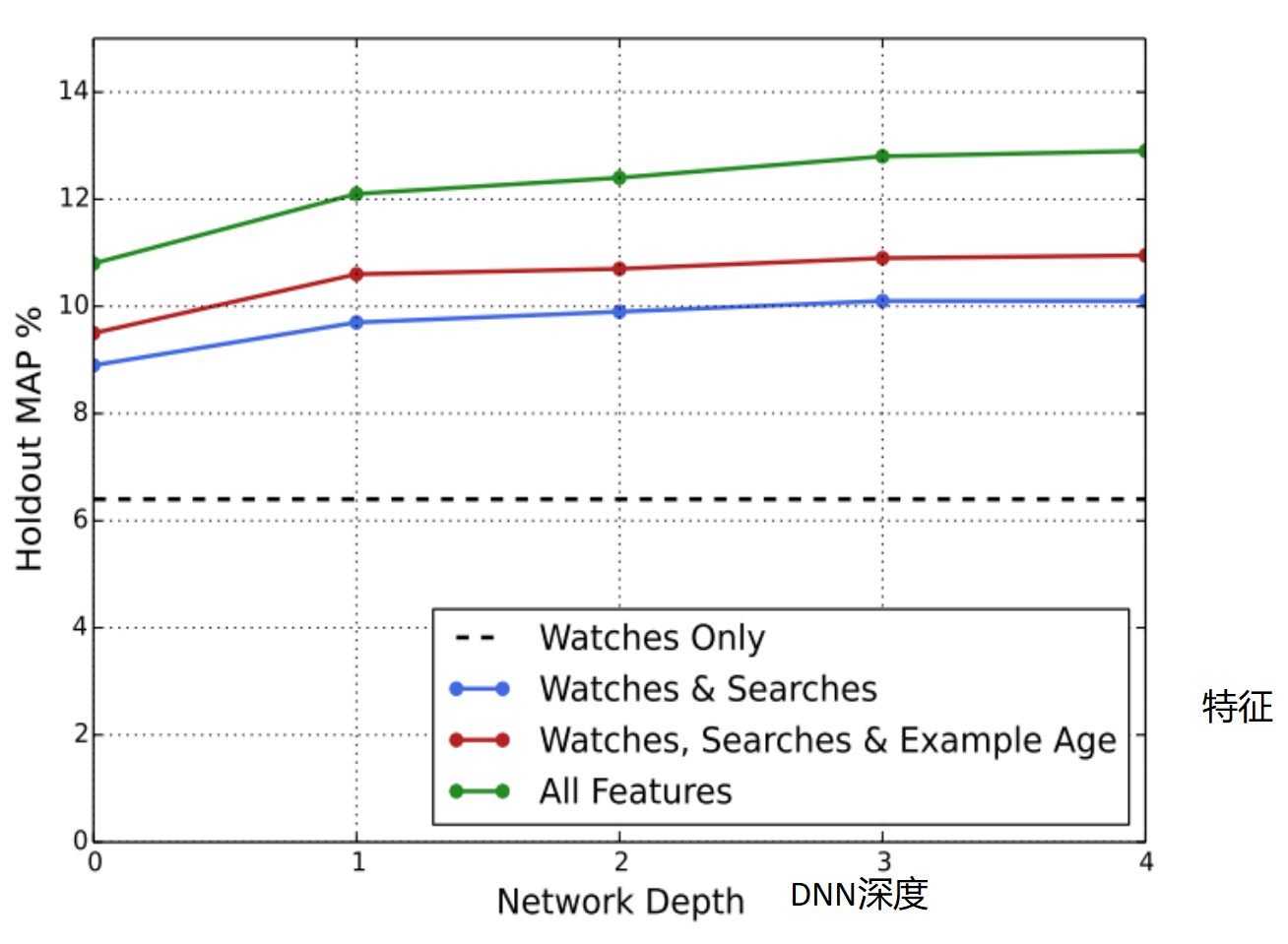
如下图所示,横轴表示深度神经网络的训练深度,纵轴表示平均精度,自变量是特征的数量,随着特征数量的增加,其平均精度呈上涨趋势,当深度神经网络达到第三层时,其平均精度不在出现”大幅度“增加。
当然考虑到CPU计算及用户可等待时长,深度神经网络的层数也不宜过多,基于实验,神经网络取3层就够了,除非以后的计算上来了才无限的增加深度神经网络的训练层数。
RANKING 排序模型
将上一层得到的几百个模型经过排序模型,评分排序,输出前面的几十个视频到用户的手机上,供用户观看。
这一层模型架构乍一看和第一层候选生成层模型一样,但是,又有一些区别。增加了很多其他的更多精细的特征,用来进行个性化的筛选。
会有人说,干嘛废那劲啊,直接一个弄一个深度神经网络模型不就行了吗,将所有的视频一起打分排序,然后输出前几十个视频到用户的主页上展示,供用户观看不就行了。
这样确实可以,一个模型解决,多方便呀。但是,你可能没有考虑一个问题,就是现在的CPU有这么高的计算能力供你计算吗?对所有的用户,所有的视频分别进行排序打分,服务器能不能承受的住,CPU计算会不会暴,就算计算能够承受下来,那会消耗多少时间,在线刷视频的用户等不等得起,毫无疑问,用户没有这么多耐心,等这个推荐系统跑完,就会换别的软件了。
而且,实在是没有必要,连第一层粗排都过不了的视频,在打分排序阶段,分数肯定太低,排不到前面去的。
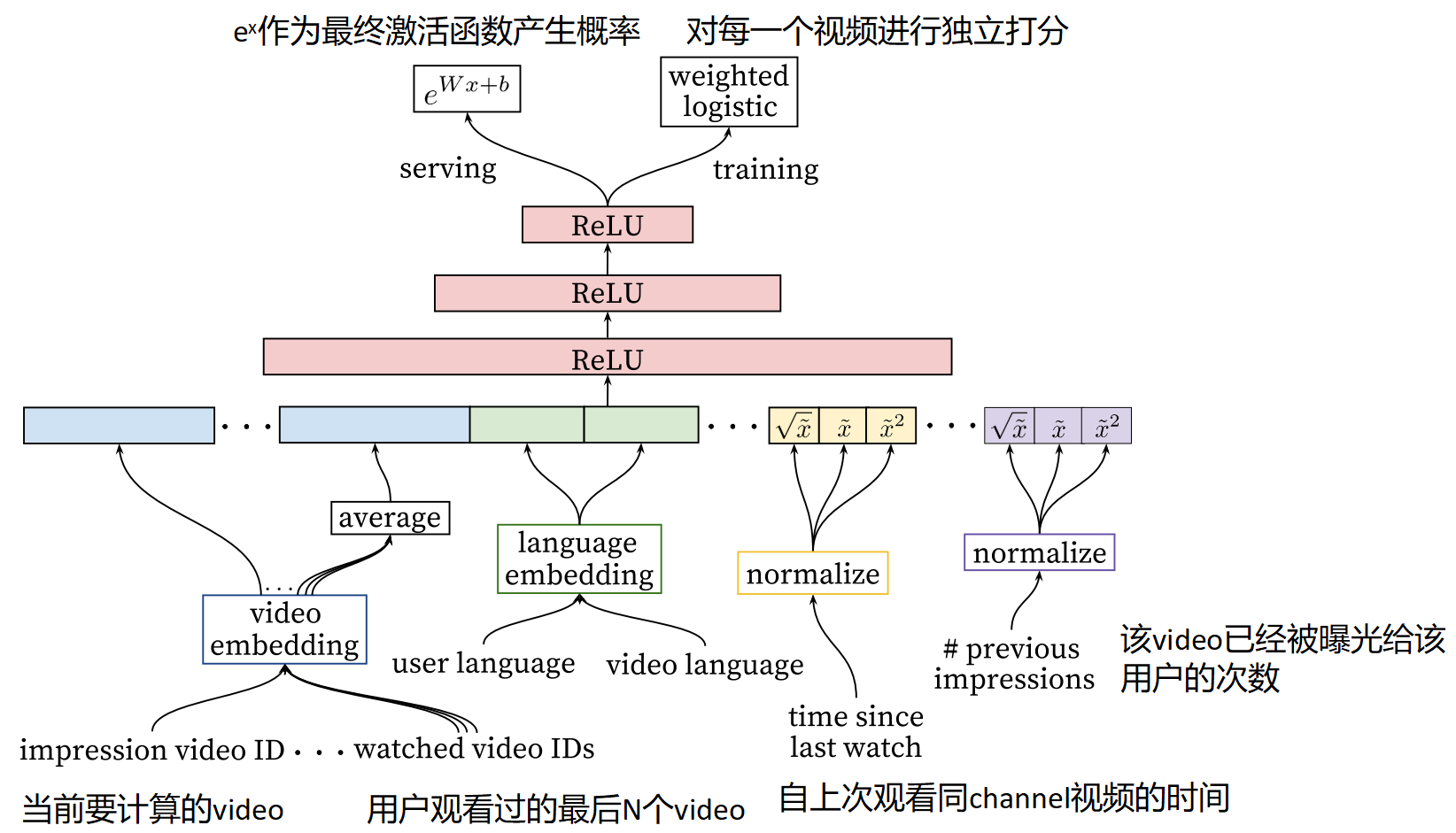
由上图所示,排序模型架构图也是自下而上的观看,新加入的特征有当前要计算的视频ID,用户光看过的最后N个ID,用户的语言,视频的语言作为语言嵌入,还有自上次观看同频道视频的时间,该视频已经曝光给该用户的次数等特征,将这些特征拼接起来,然后喂给上层的神经网络模型,训练时用加权逻辑回归为每一个视频独立打分,按照得分排序。
针对排序DNN,有如下几点需要关注:
(1) 用户对频道的喜爱程度可以通过用户对该频道的视频的点击次数来度量,用户在该频道的上次观看时间等。
(2) 类别特征embedding:作者为每一个类别特征维度生成一个独立的embedding空间。值得注意的是,对于相同域的特征可以共享embedding,其优势在于加速迭代,降低内存开销。
(3) 连续特征归一化:DNN对于输入的分布及特征的尺度敏感。作者设计一种积分函数将特征映射为一个服从[0,1]分布的变量。该积分函数为:
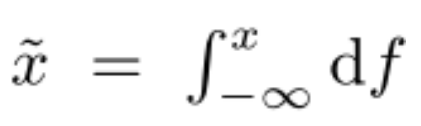
(4) 建模预期观看时长:正样本:视频被展示并被点击;按照观看时长进行加权负样本:视频被展示但未被点击;单位权重作者采用一种加权逻辑回归基于交叉熵损失进行训练。逻辑回归几率为:

那么学习概率是:E[T]*(1+P) ≈ E[T] [预期观看时间,点击率]
(5)第5个特征#previous impressions一定程度上引入了exploration的思想,避免同一个视频持续对同一用户进行无效曝光。一般来说,用户观看完一个视频后,再次观看同视频的概率大大降低,因此并不需要再次推送此视频给用户。
隐藏层实验
下图是作者进行的神经网络模型隐藏层层数的实验,可以看到随着隐藏层的层数和宽度的增加,其对于每个用户的加权损失降低,到实验达到1024–>512–>256这个网络时,其损失不在“大幅度”的减少,故选择这个配置的隐藏层即可,损失为34.6%。

而对于1024–>512–>256这个网络,测试的不包含归一化后根号和平方的版本,loss增加了0.2%。而如果把weighted LR替换成LR,效果下降达到4.1%。
CONCLUSIONS 总结
本文最突出的贡献在于如何结合业务实际和用户场景,选择等价问题,实现推荐系统。
首先,深度协同过滤模型能够有效地吸收更多特征,并对它们与深度层的相互作用进行建模,优于以前在YouTube上使用的矩阵分解方法。
其次,作者对特征的处理策略充满智慧。比如,对**example age**特征的加入,消除了对过去的固有偏见,并允许模型表示流行视频的时间依赖行为。
最后,排序阶段,对评估指标的选择能够结合业务,取期望观看时间进行训练。
个人的一些想法
这篇论文是2016年,YouTube发表的推荐系统的会议文章。
YouTube的推荐系统仅仅使用了两个模型,使用深度学习神经网络的方法进行的推荐,整体来说模型的稍微有点简单了,但是胜在快。自己使用了一下YouTube这个软件,发现其推荐算法确实有点缺点,你刷什么视频,就一直给你推荐相关视频,过于单一了,就单从推荐算法来说,还是国内的某些软件上推荐的好。可是毕竟是16年的推荐算法了,且是首次使用深度学习神经网络应用在推荐系统上,而且是已经在工业上实施的论文,可以公开让我们读到,还是很让我增长见识的。